
Dive into Deep Learning — Dive into Deep Learning 1.0.3 documentation
d2l.ai
Dive into Deep Learning 11장 Attention Mechanisms and Transformers를 공부하며 작성함
Attention Mechanism 개요
초기 딥러닝 모델은 MLP, CNN 및 RNN 구조가 사용되었고 2010년대의 모델 핵심 아키텍처 또한 클래식한 모델 구조들이 사용되었다. CV에서는 CNN, NLP에서는 LSTM 설계를 따르는 모델들이 SOTA 위치를 유지했다.
현재는 거의 모든 NLP 작업이 Trasformer 아키텍처를 기반으로 하며 ViT(Vision Transformer) 또한 기본 모델로 등장했다.
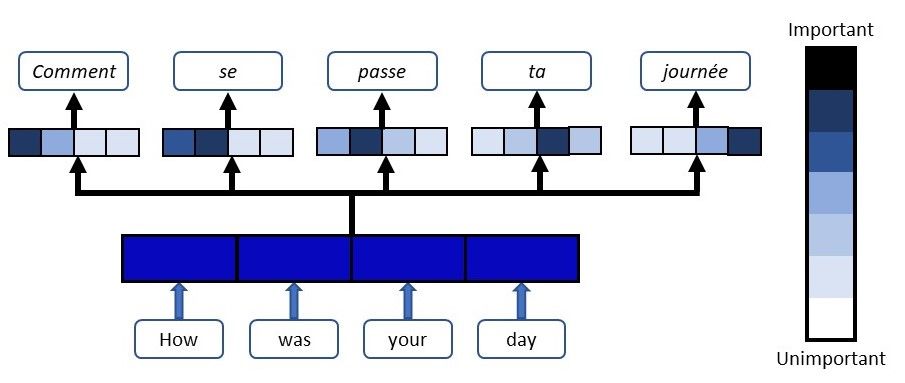
Transformer의 핵심은 Attention Mechanism으로 seq2seq 기계 번역에 활용되었다. 기존의 seq2seq 에서는 input이 인코더에 의해 벡터로 압축되어 디코더로 전달되었으나 어텐션 메커니즘은 입력을 압축하는 대신 디코더가 각 단계에서 입력 시퀀스를 다시 방문하는 것이다.
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org

attention function에서는 주어진 query에 대해서 모든 key와의 유사도를 각각 구하고 key와 매핑되어 있는 value에 반영해준다. 유사도가 반영된 value값의 합을 리턴하고 attention value라고 한다.





{(k1, v1),...(km,vm)}으로 표시되는 key와 value의 m개의 튜플로 이루어진 데이터베이스와 q(query)가 있고 가중치가 𝛼(q, k𝑖) ∈ R (𝑖 = 1, . . . , 𝑚) 을 때 어텐션을 위와 같이 정의할 수 있다. 어텐션 연산은 어텐션 풀링으로 참조되며 가중치 𝛼가 중요한(큰) 항목에 집중하기 때문에 어텐션 메커니즘이라는 이름이 붙었다. 어텐션 메커니즘은 가중치가 음수가 아니고 가중치의 합이 1일 때 특히 직관적이라는 장점을 가지는데 이를 시각화하기 위해서 히트맵을 그릴 수 있다.
By design, the attention mechanism provides a differentiable means of control by which a neural network can select elements from a set and to construct an associated weighted sum over representations.
어텐션 메커니즘은 신경망이 집합에서 요소를 선택하고 관련된 가중합을 구성할 수 있는 미분 가능한 제어 수단을 제공한다.
Attention Pooling


KDE(Kernel Density Estimation)을 통해 회귀와 분류에서 어텐션을 사용해보려고 한다.
KDE(커널 밀도 추정)란 커널 함수를 이용한 밀도 추정 방법이다. 데이터들의 분포로부터 원래 변수의 분포 특성을 추정하고자 하는 것이 밀도 추정이라면 KDE는 커널 함수를 이용해 기존 밀도 추정 방법의 단점을 개선한 것이다. 수학적으로 커널함수는 원점을 중심으로 좌우대칭이면서 적분값이 1인 non-negative 함수로 정의되며 균등 함수, 가우시안 함수 등이 있다.
Kernel Density Estimation (커널 밀도 추정) · Seongkyun Han's blog
Kernel Density Estimation (커널 밀도 추정) 03 Feb 2019 | kernel density estimation KDE 커널 밀도 추정 Kernel Density Estimation (커널 밀도 추정) CNN을 이용한 실험을 했는데 직관적으로는 결과가 좋아졌지만 왜 좋아
seongkyun.github.io
yi=2sin(xi)+xi+ϵ 를 따르는 훈련 데이터 40개를 생성하여 Nadaraya-Watson KDE를 실제로 볼 수 있다. 잔차는 평균이 0이고 분산이 1인 정규 분포를 따른다. 커널과 데이터를 생성한 뒤에는 커널 회귀 추정 함수를 정의하는데 먼저 xtrain과 xval 간을 커널을 계산한다.
def nadaraya_watson(x_train, y_train, x_val, kernel):
dists = x_train.reshape((-1, 1)) - x_val.reshape((1, -1))
# Each column/row corresponds to each query/key
k = kernel(dists).type(torch.float32)
# Normalization over keys for each query
attention_w = k / k.sum(0)
y_hat = y_train@attention_w
return y_hat, attention_w
x_train을 열 벡터로, x_val을 행 벡터로 변환하고 두 벡터 집합 간의 거리를 계산하여 커널 함수에 입력으로 들어가게 된다. 만들어진 행렬 dists는 query와 key 간의 대응을 나타내며 x_val 이 새로운 입력(query), x_train이 훈련 데이터의 입력(key)으로 dists 행렬의 각 원소 (i, j)는 x_train[i] - x_val[j] 즉 query와 key 간의 거리를 나타낸다.

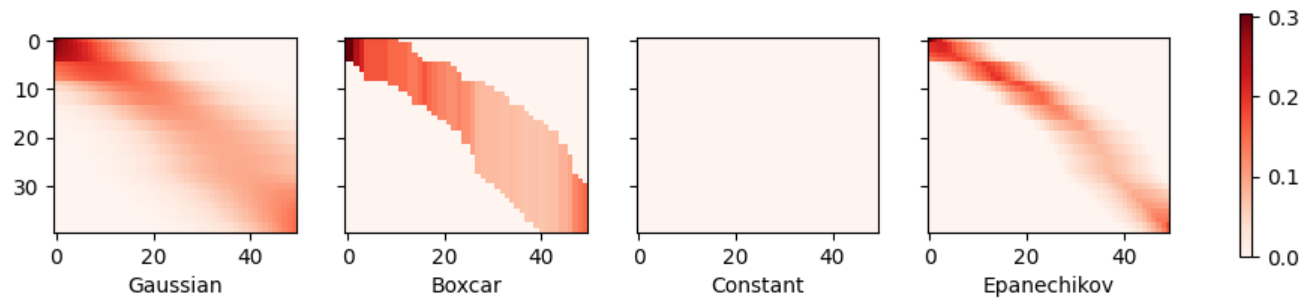
Gaussian, Boxcar, Epanechnikov 세 가지 비자명한 커널이 모두 유효한 추정치를 생성하며 실제 함수에서 크게 벗어나지 않는다는 것을 확인할 수 있다. 상수(constant) 커널은 실질적이지 않은 결과를 생성하여 예외로 둔다.
히트맵으로 살펴본 Gaussian, Boxcar, Epanechikov 세 커널함수에 대한 추정치 또한 매우 유사한데 그 이유는 커널 함수 형태가 다르더라도 이 커널 함수들이 생성하는 어텐션 가중치가 유사하기 때문이다.



가중치 계산 식에서 σ^2(커널 함수의 분산) 의 값을 변경하여 커널의 폭을 변경할 수 있다. 커널이 좁아질수록 유사도가 덜 부드러우며 local variations에 민감해진다. 반대로 커널이 넓을수록 유사도는 더 평탄해지고 global한 특징을 반영한다.
항상 동일한 커널 폭을 선택하는 것이 이상적이지 않을 수 있다. Silverman(1986) -A Heuristic Subexponential Algorithm to Find Paths in Markoff Graphs Over Finite Fields에서 local density에 의존하는 휴리스틱을 제안했고 Norelli et al.(2022)-ASIF:Coupled Data Turns Unimodal Models to Multimodal Without Training에서 멀티 모달 이미지 및 텍스트 표현을 디자인하기 위한 기술로 nearest-neighbor interpolation 기술을 소개하는 등 많은 트릭이 제안되었다. 하지만 커널 밀도 추정 메서드는 어텐션 매커니즘 초기 모습 중 하나이며 시각화하기 좋고 손으로 만든 어텐션 매커니즘의 한계를 보여주기 때문에 학습할 가치가 있다. 좀 더 나은 어텐션 매커니즘 전략으로는 query와 key에 대한 표현을 학습하여 매커니즘을 학습하는 것이다.
Attention weight is assigned according to the similarity (or distance) between query and key, and according to how many similar observations are available.
'ML·DL > PyTorch DL' 카테고리의 다른 글
| Attention & Transformer (2) (1) | 2023.12.26 |
|---|---|
| 신경망 입문 - CNN (1) | 2023.11.22 |
| 딥러닝 입문 (0) | 2023.11.13 |