신경망 입문 - CNN
CNN 모델과 특징 소개
| CNN 모델 | 특징 | ||
| VGG | 가장 기본이 되는 CNN. VGG 이전의 CNN은 커널 크기가 커서 학습해야 하는 가중치의 수가 많았지만 VGG는 3x3 크기의 커널을 이용해서 가중치 개수를 줄일 수 있음. torchvision.models.vgg16() |
||
| ResNet | 입력 이미지와 특징 맵(feature map)을 더하는 CNN. 층이 깊어질수록 역전파되는 오차가 작아지는 문제를 어느 정도 해결함. 그로 인해 VGG와는 비교도 안 되는 깊이를 가짐. CNN 모델 중에서 ResNet이 가장 많이 사용됨 torchvision.models.resnet18() |
||
| Inception | 3x3 커널을 여러 번 중첩해 크기가 큰 커널을 근사함. VGG보다 넓은 시야를 갖게 됐으며 큰 크기의 커널보다 적은 수의 가중치로 비슷한 효과를 얻음 |
||
이미지 정규화(normalization)
학습 속도와 성능을 위해 편향돼있는 R, G, B 값을 정규화해줘야 한다.
색이 정규분포를 따르도록 값을 바꾸면 색도 변하지만 인공지능 입장에서는 색이 갖는 분포가 일정해야 학습이 제대로 이뤄진다고 한다.
컴퓨터는 색맹인가??
37. [CNN기초] 다채널(multi channel) 다루기
이전 시간까지 1개 채널을 가진 이미지를 1개의 필터를 이용하여 특성을 추출한 후 학습을 진행하였다. 1개 채널을 가진 이미지로 만들기 위해 흑백이미지(Grayscale)로 만들어 학습시켰다. 하지만,
toyourlight.tistory.com
CNN에서 색상 처리하는 방법을 찾아보니 채널이라는 이미지의 색상에 대한 정보를 담은 객체를 이용하여 다룬다고 한다.
VGG 이미지 분류
전이 학습(transfer learning): 다른 데이터를 이용해 학습된 모델을 갖고 있는 데이터에 최적화시키는 학습 방법. 일반적으로 대용량 데이터를 이용해 사전 학습한 모델을 소규모 데이터에 최적화시킴
전이 학습의 설명이 파인 튜닝과 유사한 것 같아서 차이점이 궁금해짐.
Transfer learning : 학습된 모델을 기반으로 최종 출력층을 바꿔 학습
ex)여러 클래스로 동물들을 분류하는 모델인 VGG를 개와 고양이 분류로 전이학습
Fine tuning: 모든 층의 파라미터를 다시 학습
*스터디원 분이 말씀해주셨는데 전이 학습도 파인 튜닝과 비슷하게 쓰인다고 하심
=> Fine tuning은 Transfer learning의 한 방법으로 요즘은 Transfer learning이라고 하면 주로 Fine tuning을 의미함
ResNet: 스킵 커넥션 사용 CNN 모델

ResNet은 152개 layer까지 쌓을 수 있게 되었는데 backward gradient나 forward responses가 쉽게 vanishing하거나 explode하는 문제가 있었지만 이를 ReLU 활성화 함수로 해결할 수 있었기 때문이다.
Batch Normalization
- improve smoothness of loss landscape
- accelerate training
- less sensitive to initialization
- improve regularization
Degradation Problem
모델이 깊어질수록 optimize 하기 어렵기 때문에 레이어를 깊이 쌓았을 때 모델이 수렴하고 있음에도 불구하고 loss가 커지는 문제이다. 이를 해결하기 위해서 제시한 솔루션이 스킵 커넥션이다.
스킵 커넥션으로 degradation problem을 해결할 수 있을 뿐만 아니라 vanishing gradient 문제도 해결했으며 relative shallow network에서 앙상블 효과가 있어 성능 개선이 이루어졌다.
스킵 커넥션: 은닉층을 거치지 않은 입력값과 은닉층의 결과를 더하는 구조
Skip Connection
신경망 모델 학습 시 모델의 층이 깊어질수록 학습 결과가 좋다.하지만 층을 또 너무 깊게 쌓아버리면 문제가 생긴다.멀리서 말하는 사람의 목소리가 잘 안들리듯이, 모델이 깊어질수록 모델의
velog.io

ResNet은 VGG 등에 비해 파라미터 수가 적고 낮은 complexity, inference time, model size를 갖지만 성능이 더 좋아짐.
Identity Mappings in Deep Residual Networks
Deep residual networks have emerged as a family of extremely deep architectures showing compelling accuracy and nice convergence behaviors. In this paper, we analyze the propagation formulations behind the residual building blocks, which suggest that the f
arxiv.org
torchvision.models — Torchvision 0.8.1 documentation
torchvision.models The models subpackage contains definitions of models for addressing different tasks, including: image classification, pixelwise semantic segmentation, object detection, instance segmentation, person keypoint detection and video classific
pytorch.org
참고한 ResNet 논문과 torch vision 모델 정보
이미지 세그멘테이션 U-Net
U-Net은 Biomedical 분야에서 Image Segmentation을 목적으로 제안된 Encoder-Decoder 구조 모델이다. 이미지의 모든 픽셀을 분류하는 이미지 세그멘테이션 모델로 인코더는 입력받은 이미지를 합성곱을 이용해 특징을 추출하고, 디코더에서 복원되어 픽셀을 분류한다.
U-Net: Convolutional Networks for Biomedical Image Segmentation
U-Net: Convolutional Networks for Biomedical Image Segmentation Medical Image Computing and Computer-Assisted Intervention (MICCAI), Springer, LNCS, Vol.9351: 234--241, 2015 Abstract: There is large consent that successful training of deep networks require
lmb.informatik.uni-freiburg.de
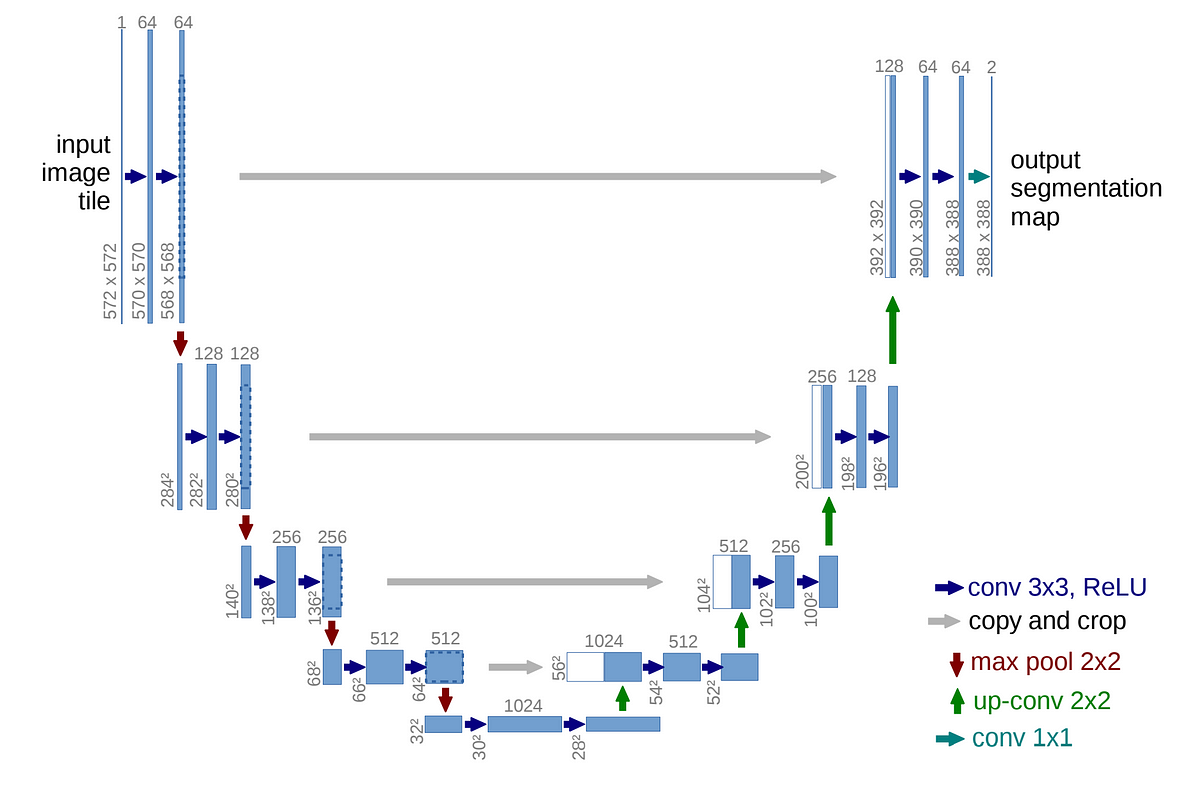
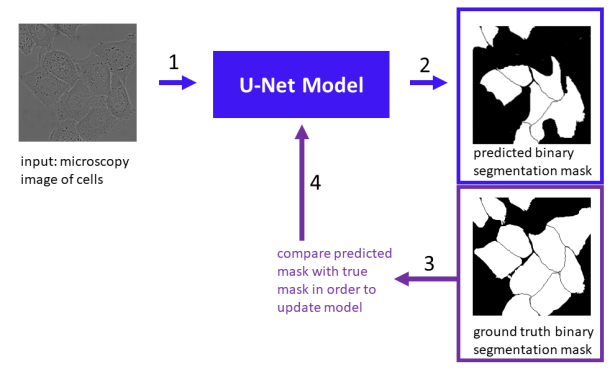
작은 데이터셋에 학습시켜도 좋은 성능이 나오는 모델이며 다른 segmentation 모델들과 다르게 세포들을 각각 개별 인스턴스로 생각하지는 않고 같은 클래스로 구분한다고 한다.

U-Net 아키텍처는 계산의 효율성이 필요하거나 픽셀 단위로 이미지를 구분할 필요가 있을 때 사용한다.
수축 경로에서는 Downsampling, 확장 경로에서는 Upsampling을 반복하며 피처맵을 생성하고 Bottle Neck에서는 모델을 일반화하고 robust하게 만든다. contracting path(수축 경로)에서는 활성화 함수로 ReLU를 사용하며 피처맵의 너비와 높이를 줄이면서 kernel을 2배로 늘리며 채널의 크기를 늘린다. expanding path(확장 경로)에서는 피처맵의 너비와 높이를 늘리면서 contracting path의 피처맵과 concatenation을 통해 합친 뒤 kernel의 개수를 반으로 줄인다. 채널의 개수를 줄이는 이유는 위에서 언급했던 것과 같이 세포들을 각각 개별 인스턴스로 생각하지 않고 같은 클래스로 구분하기 때문에 최종적으로 foreground, background 2개의 클래스로 판단하기 때문이다.
U-Net PyTorch 실습
GitHub - hayashimasa/UNet-PyTorch: PyTorch implementation of the U-Net architecture
PyTorch implementation of the U-Net architecture. Contribute to hayashimasa/UNet-PyTorch development by creating an account on GitHub.
github.com
UNET_pytorch_Notebook.ipynb
drive.google.com



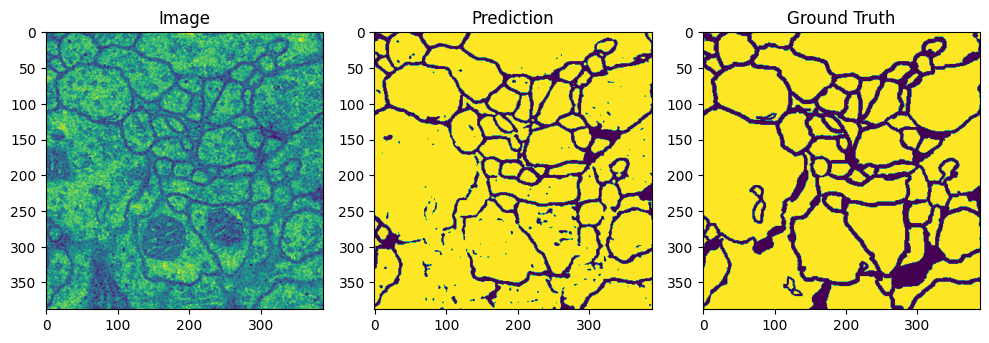

학습 결과 Loss 값은 매우 잘 나왔으며 세포의 윤곽을 잘 잡아내는 것을 확인할 수 있었다. 세포핵은 잘 잡아내지 못하는 것으로 보인다.
Auto Encoder
오토인코더는 U-Net과 비슷하게 인코더/디코더 구조를 이용한다. 오토인코더는 입력을 그대로 출력으로 내보내도록 학습되는데 따라서 노이즈가 있더라도 원본을 복원할 수 있는 장점을 가진다. 이미지 디노이징, 인페인팅, GAN에서 사용하며 합성곱을 사용하는 오토인코더를 CAE(convolutional autoencoder)라고 한다.
CAE.ipynb
Colaboratory notebook
colab.research.google.com


인코더 모델은 기본 블록을 거치고 풀링층을 거치는 구조이다. MNIST 데이터는 학습하기 쉬운 데이터셋이므로 16채널로 설정한다. 인코더와 디코더는 대칭적으로 구성하는게 좋은데 인코더에서 기본 블록을 두 번 호출했기 때문에 디코더에서도 기본 블록을 두 번 호출해준다. 디코더에서는 풀링 대신 업샘플링층이 존재하고 출력층은 활성화 함수를 이용해 값을 변경하면 안되므로 기본 블록 대신 합성곱층을 사용한다.


성능은 한눈에 보기에도 매우 좋아보였다.
학습 중