Swin Transformer
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as
arxiv.org
CNN을 사용하지 않아서 접근 방법이나 데이터가 돌아가는게 기존의 방식과는 매우 달라짐
ViT(Vision Transformer)
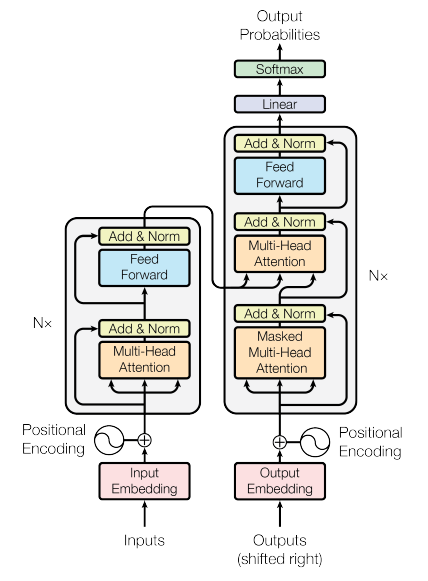

positional encoding: 한 문장에서 해당 단어가 차지하는 포지션을 벡터의 형태로 변환해서 입력을 넣어주는 것
multi head attention 모듈을 skip connection과 addition, normalization 수행해주고 feed forwardg하는 과정을 n번 반복해준다. masked multi head attention 모듈은 아직 생성이 되지 않은 부분을 마스킹 해준다.
이전 모델들은 입력한 문장을 global한 representation으로 변형하고 representation에서 또 다른 언어로 mapping하는 과정(bottle neck)에서 information loss가 발생함
=> transformer는 information loss를 최소화하여 attention만으로 원하는 문장을 찾고 원하는 의미로 변형

swin transformer가 지금 CV에서 아주 핫한 sota 모델이다.
transformer는 엄청난 양의 데이터, 학습량이 필요하기 때문에 리소스가 풍부해야함

구조는 기존의 transformer에서 글자를 patch로 바꿨다고 생각하면 된다. 이미지 패치의 위치에 따라 포지션 인코딩을 진행하고 패치와 함께 임베딩한다.
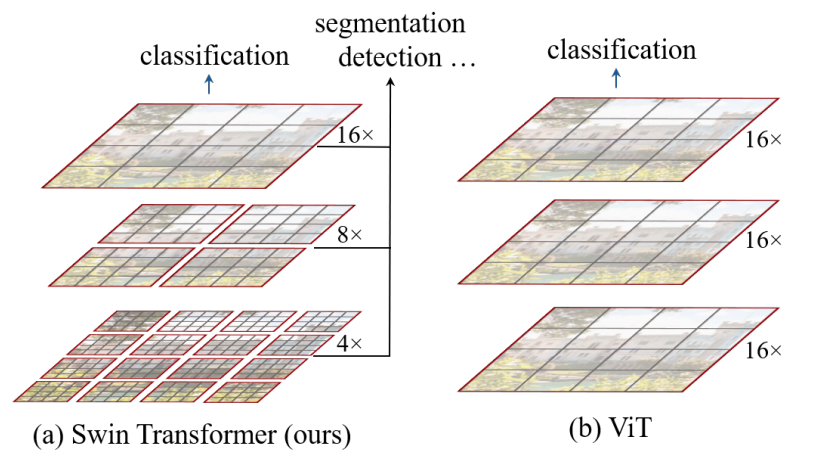


swin transformer에서는 패치를 잘게 쪼갠 어텐션부터 크게 쪼갠 어텐션까지 hierarchical한 피처맵으로 만들어 한번에 볼 수 있다. 그리고 layer에 따라 윈도우 기준으로 어텐션을 계산하는데 윈도우의 위치를 바꾸면서 계산한다.
shifted window attention을 구하는 과정은 위와 같이 좌상단 부분의 패치들을 반대쪽에 붙여주는 것이다. 이때 positional embedding 값이 함께 학습이 되기 때문에 위치가 변해도 학습이 가능하다. => shifted window 방식이 왜 모델 성능에 도움이 되는지 의문이 생겼으나 검색으로는 해결하지 못함:featuremap을 생성할 때 단순히 패딩을 진행하면 연산량이 많아지고, 이미지 패치들의 크기를 맞춰주기 위하여 shifted window attention을 활용한다.

swin transformer는 가장 작은 패치의 단위를 4x4로 잡기 때문에 H/4 * W/4는 패치, 토큰의 갯수라고 생각할 수 있으며 차원을 맞춰주기 위해 48을 곱해준다. stage2의 블록에서는 패치 사이즈가 줄어들면서 채널의 크기가 커지고 그 과정을 stage4까지 반복한다. 이러한 구조는 cnn, resnet과 유사하다고 생각할 수 있다.
swin transformer의 블록은 기존 vision transformer에서 쓰는 블록의 구조와 유사하다. 공통적으로 LN(layer normalization)와 MLP 층을 가지고, W-MSA(window multi-head self attention), SW-MSA(shifted window multi-head self attention) 층을 추가적으로 가진다.
Swin Transformer Pytorch 실습
GitHub - microsoft/Swin-Transformer: This is an official implementation for "Swin Transformer: Hierarchical Vision Transformer u
This is an official implementation for "Swin Transformer: Hierarchical Vision Transformer using Shifted Windows". - GitHub - microsoft/Swin-Transformer: This is an official implementation...
github.com
작성중
+plus
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
transformer 등장한 논문
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
transformer를 처음으로 computer vision에 적용한 논문
위 논문들도 시간이 된다면 읽어보는 것이 좋을듯하다.